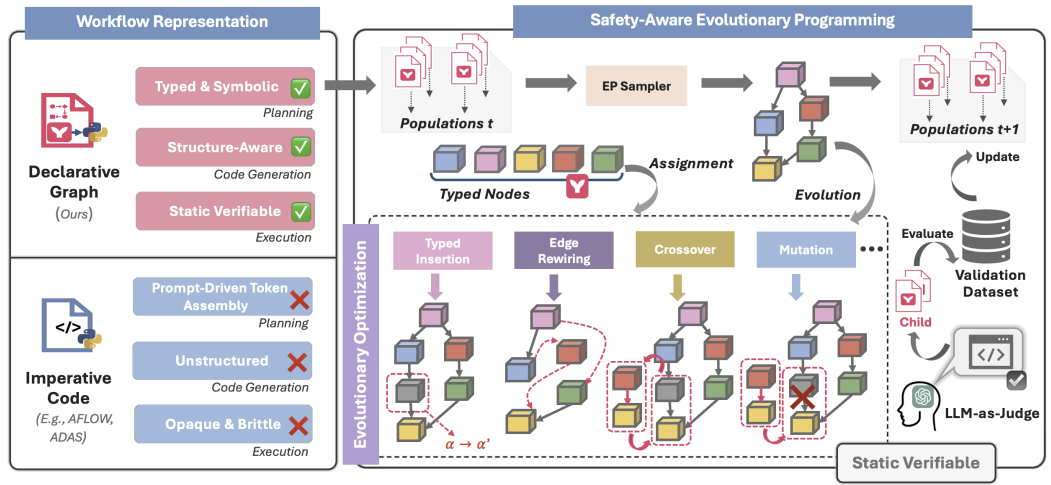
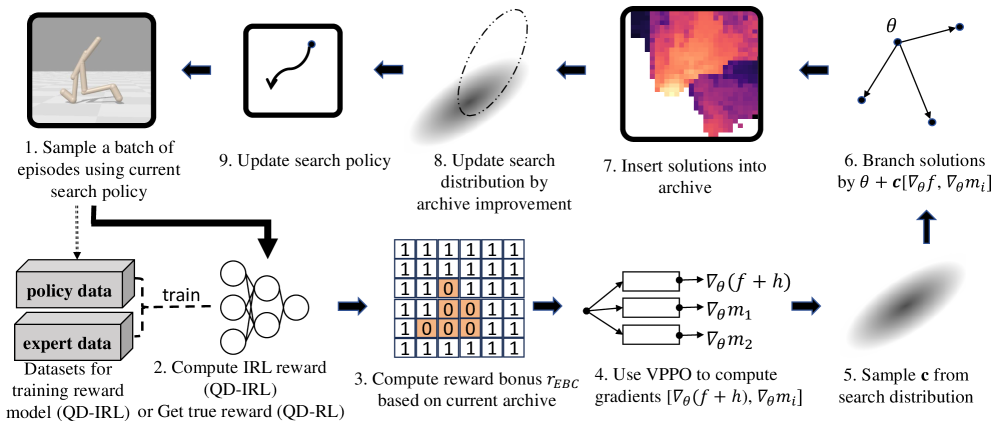
- AI for Science
- Theory and Optimisation in AI
- Artificial General Intelligence
- Sustainable AI
- Resilient & Safe AI
Artificial General Intelligence (AGI)
Artificial General Intelligence (AGI) is increasingly framed as the pursuit of general-purpose agents that learn, plan, and adapt in open-ended environments, moving beyond the task-bound paradigm that has long defined conventional AI. These emerging systems build on prior experience to tackle unfamiliar challenges, reason over long-term objectives, and adapt fluidly as their worlds evolve. By accumulating knowledge that endures and compounds over time, they begin to drive discovery rather than merely execute predefined tasks, marking a decisive step toward general intelligence.
The pathway to AGI lies not simply in scaling models, but in expanding the scope of what intelligence can achieve. Each generation of systems has widened this horizon: from rule-based programmes that encoded explicit knowledge, to learning algorithms that extracted patterns from data, to large-scale models that generalise across tasks. Building on these foundations, today’s agentic systems are beginning to operate autonomously, plan over long horizons, and adapt continually. This trajectory is converging toward high-capacity AGI systems where agents can grow within open-ended worlds, self-improve through experience, and drive discovery across domains.
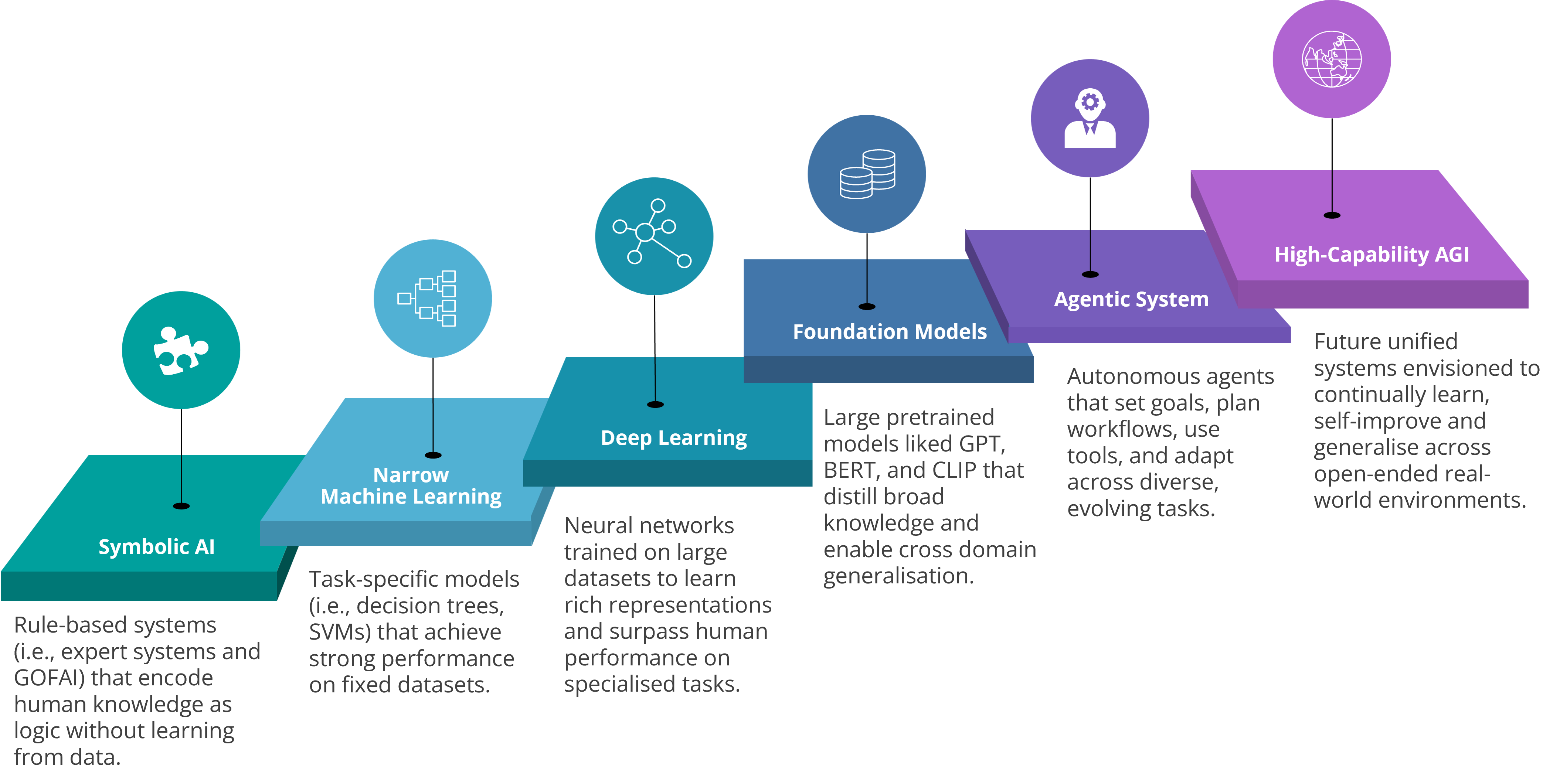
Fig. 1 Pathway to AGI
Core Capabilities
At A*STAR CFAR, we explain general intelligence through four primary capabilities:

- Agency endows agents with the autonomy to set their own goals, plan over long horizons, and coordinate actions to achieve them.
- Grounding anchors abstract representations in real-world perception and interaction, enabling knowledge to reflect the true structure of the world.
- Adaptivity allows agents to reshape their policies through experience, improving with every encounter and generalising across tasks, environments, and timescales.
- Prediction equips agents to model their environment, anticipate consequences, and choose actions that shape desired futures.
These capabilities form the foundation for intelligence to be open-ended, continually learning, discovering, and pushing the boundaries of what is possible.
Research Pillars
Progress toward AGI requires integrating decision-making, reasoning, generation, and embodiment into a coherent system of continually expanding capabilities. Our research is anchored in four closely interconnected pillars:
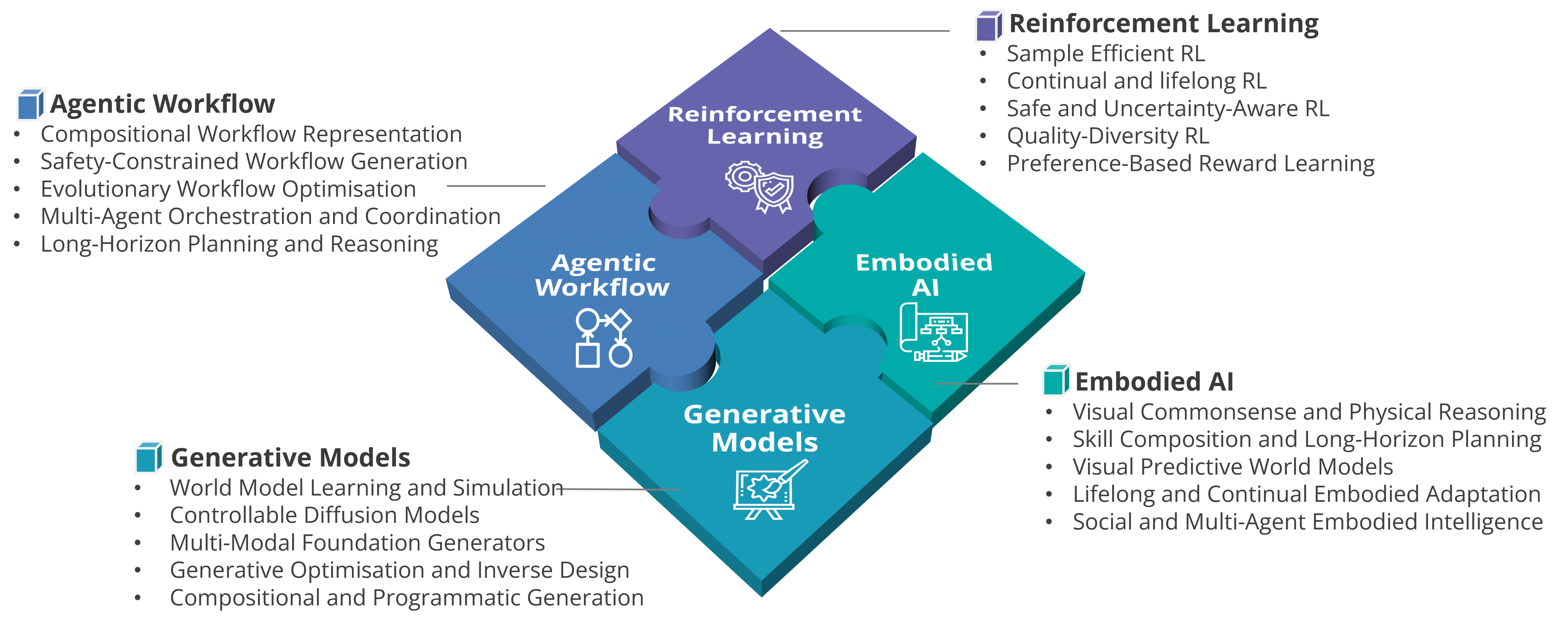 Fig. 2 A*STAR CFAR's core pillars of AGI research
Fig. 2 A*STAR CFAR's core pillars of AGI research