- AI for Science
- Theory and Optimisation in AI
- Artificial General Intelligence
- Sustainable AI
- Resilient & Safe AI
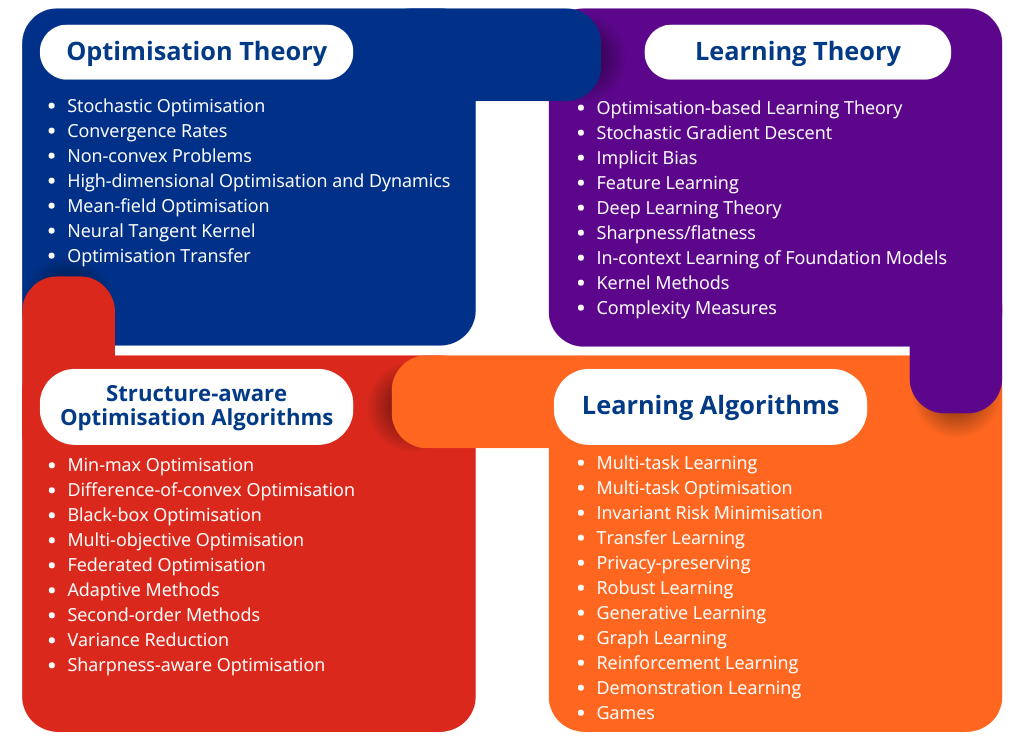
Theory and Optimisation in AI
Artificial intelligence has achieved remarkable success in many tasks, such as object and speech recognition, game AI, robot control, drug discovery, molecule design, and foundation models. This success is attributed to massive datasets, huge computational resources, and the great expressive power of high-dimensional models such as deep neural networks. However, building a large model on a massive dataset entails significant costs. Hence, reducing the required amount of data and compute remains an imperative research direction. In short, the next generation learning methodologies must be:

Optimisation forms the foundation of many AI applications, as training AI models is essentially similar to solving a high-dimensional optimisation problem. Hence, improving optimisation performance and analysing its behaviour could directly bring the above features to many learning methodologies.
Optimisation-based Learning Theory
While overparameterised models, such as deep neural networks, offer many solutions that fit the training dataset, their generalisation capabilities can vary. As the nature of the solution obtained is dependent on the optimisation method, all aspects, including optimisation, modelling, and regularisation need to be studied comprehensively to understand the mechanism behind modern AI systems. Through optimisation-based learning theory, we aim to understand the reasons behind the superior performance of deep learning, including its high prediction accuracy, exceptional adaptability of foundation models to downstream tasks, and ability to perform in-context learning.
Learning problems often exhibit special problem structures depending on their purpose and context. Therefore, it is important to design optimisation methods that utilise these structures to enhance performance.
Here, we focus on the following research areas: