
The emergence of the systems biology field in recent decades marks a radical methodological and conceptual shift in the way living organisms are studied. Where much has and continues to be learned from traditional approaches in understanding the individual processes of living organisms, systems biology aims to shed light on the unknowns of gene regulations, signal transductions and metabolic networks by considering them more holistically. Though generally thought to be too convoluted to permit predictability, the mathematical and computational tools and techniques of systems biology are increasingly allowing this new field of research to make reasonably accurate estimations about the inner regulations and behaviors of life.
The Computational Biology and Omics laboratory embraces systems biology, and is interested in understanding biological complexities such as disease onset and progression, non-linear self-organization, emergent behaviors as well as synthetic biology and biotechnological applications. Thus, our team members are highly skilled in mathematics, computer programming, data analytics and machine learning; to develop original methods for the analyses of high-throughput and time-series transcriptomics, proteomics, and metabolomics datasets and for modeling biological network dynamics across diverse cell types. To briefly illustrate, dynamic metabolic networks models are developed to predict how we can increase production of certain compounds of interest such as limonene (Figure 1). Space-time models are also used to infer post-treatment effects and reveal state transitions (Figure 2). Such approaches reduce laborious experiments, thereby saving valuable time and cost for projects.
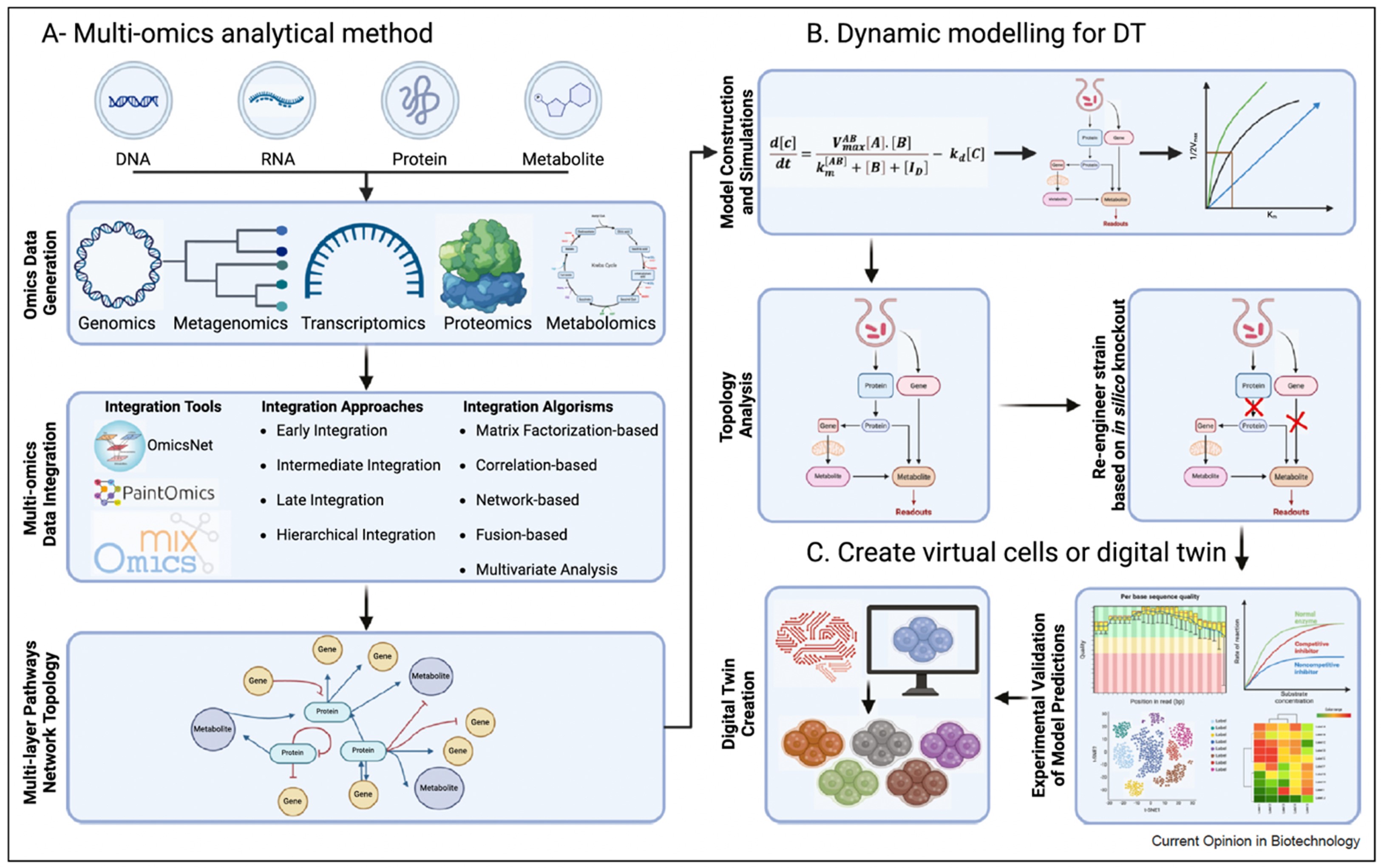
On the other hand, to tackle large-scale omics data, we are developing cutting-edge methodologies to interpret the complex and multi-dimensional datasets. For example, data-driven and process- driven synthetic data generators are being developed to predict the transcriptional patterns and mechanisms of differentially expressed genes between control and disease (Figure 3). Moreover, to integrate dynamic models with machine learning models, we are working on Digital Twin approaches to deal with personalized variations between individuals in any disease and for biotechnological applications (Figure 4).
Our lab closely collaborates and works with different groups within A*STAR, local and international universities as well as with industries. Although we take pride in our primary research goals in systems biology, we share our experiences with other teams in a highly collaborative manner for synergistic outcomes.
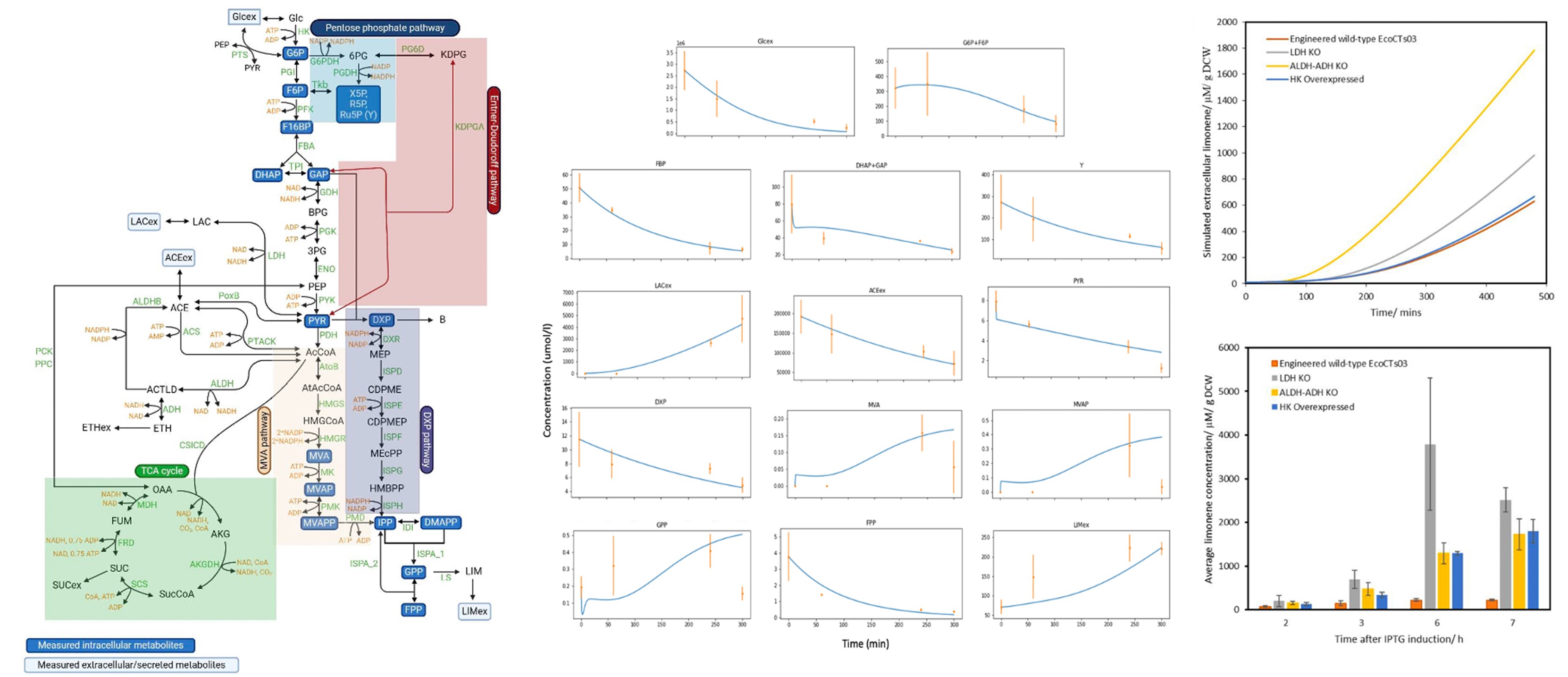
Figure 1: Dynamic modelling, using differential equations, for enhancing limonene biosynthesis, with corresponding experimental data to test model predictions. Figure adapted from [Khanijou et al, 2024].
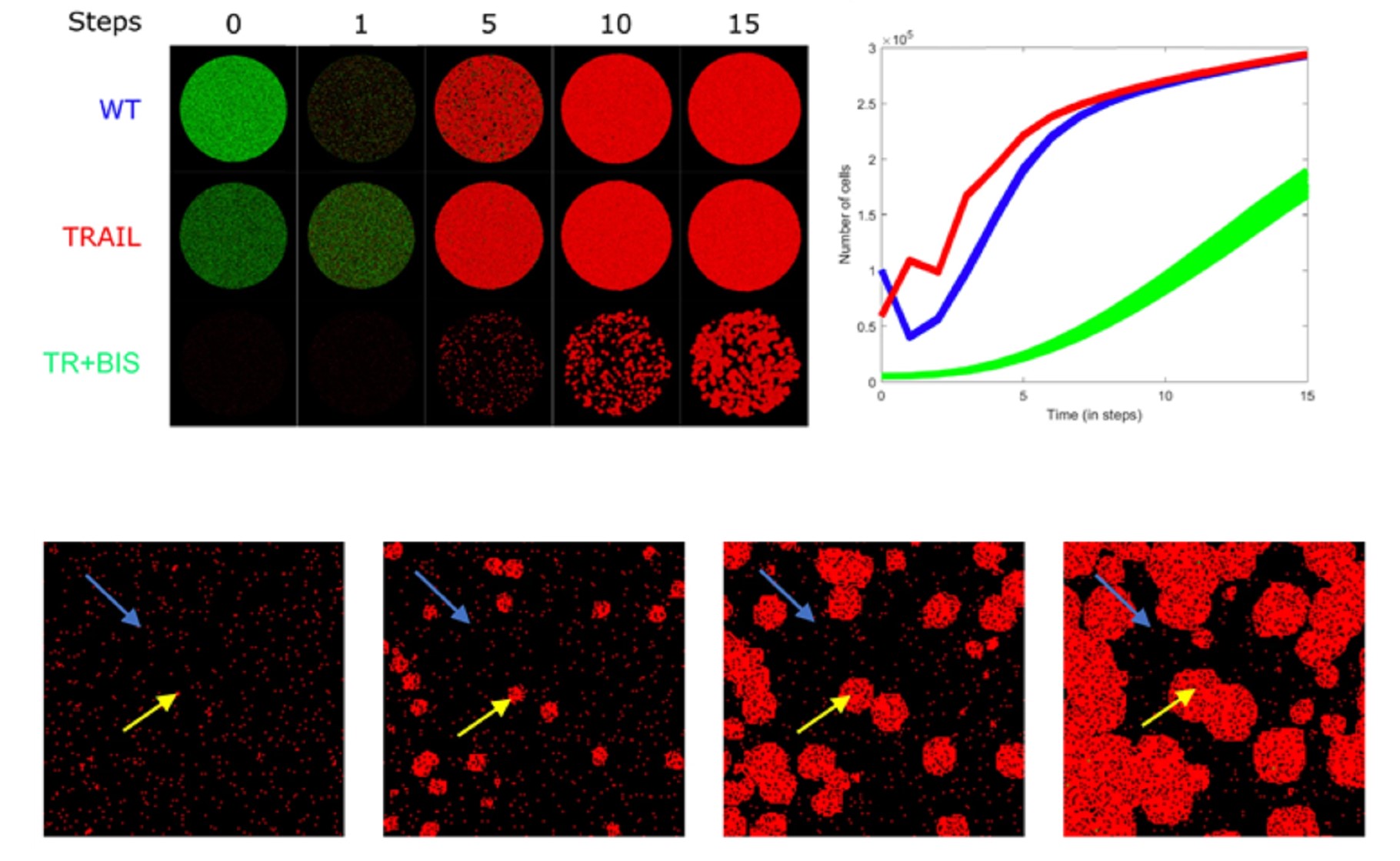
Figure 2: Space-time simulation of cancer proliferation in untreated and treated condition, revealing epithelial- mesenchymal state transition [Deveaux et al, 2019]
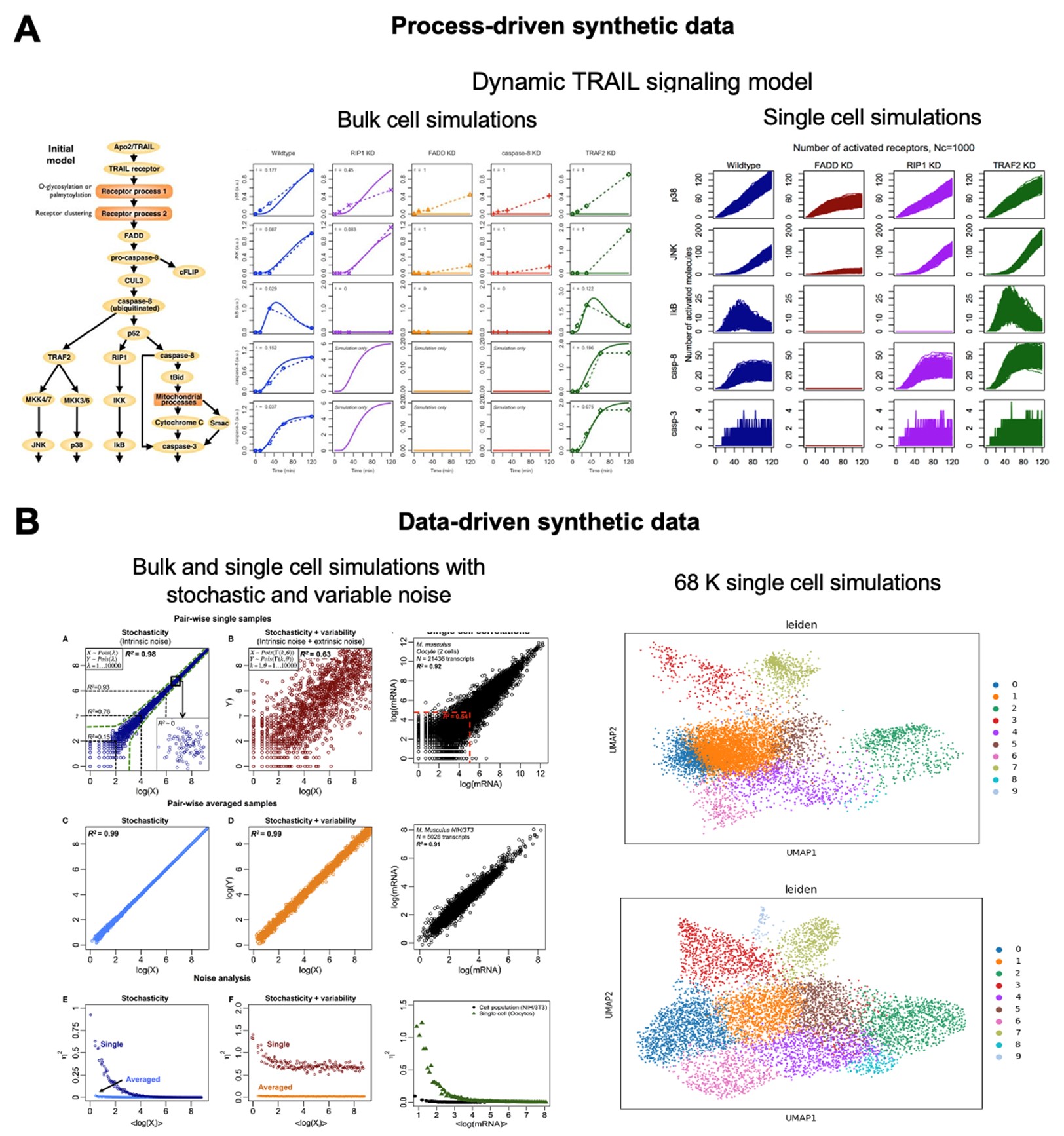
Figure 3: Synthetic data generation using process driven models (A), and data driven models (B). See details and figure adapted from Selvarajoo & Maurer-Stroh 2024.
| Senior Principal Investigator | SELVARAJOO Kumar | [View Bio] |
| Senior Scientist | YEO Hock Chuan |
| Scientist | RASHID Md Mamunur |
| Senior Research Officer | YUAN Sin Yi |
 | SELVARAJOO Kumar Senior Principal Investigator Email: kumar_selvarajoo@a-star.edu.sg Research Group: Computational Biology & Omics Lab Lab Website: https://www.cbio-kumar.org/home Research Gate: https://www.researchgate.net/profile/Kumar-Selvarajoo |
Dr. Kumar Selvarajoo is heading the Computational Biology & Omics laboratory at BII, A*STAR. He is also an adjunct Associate Professor at the Yong Loo Lin School of Medicine, National University of Singapore and the School of Biological Sciences, Nanyang Technological University. Prior, he was an Associate Professor in Systems Biology at the Institute for Advanced Biosciences, Keio University, Japan. He serves the editorial board of BMC Biology (SpringerNature), Genomics (Elsevier), Frontiers in Immunology (Frontiers) and Biotechnology Notes (KeAi). He leads in Computational Biology, Systems Biology, Bioinformatics, Data Analytics and Statistical Genetics. In particular, he has used original ideas, utilizing fundamental physical and statistical laws, to investigate multi-dimensional datasets, deterministic and stochastic modelling of complex protein signaling and metabolic networks. He has authored over 82 scientific articles, largely as corresponding author, which includes a single-authored book on Immuno Systems Biology (Springer) and edited a Methods in Molecular Biology book series on Computational Biology and Machine Learning for Metabolic Engineering and Synthetic Biology (Humana Press). He has obtained several research grants and has been an international grant reviewer and PhD thesis examiner. He has also presented invited/keynote talks at numerous international conferences.
Computational Biology, Systems Biology, Bioinformatics, Data Analytics & Machine Learning, Genomics, Cancer & Immunology, Synthetic Biology, Synthetic Data, Multi-omics Analytics
| Senior Scientist | YEO Hock Chuan |
| Scientist | RASHID Md Mamunur |
| Senior Research Officer | YUAN Sin YI |