
Data Management
We are a team of computational scientists from diverse educational backgrounds (biology, engineering, physics, medicine, mathematics) based at the Singapore Institute for Clinical Sciences and the Bioinformatics Institute. Our central mission is to identify the determinants of population health using molecular profiling and machine learning approaches. The cohorts we investigate are composed of individuals affected by complex health conditions (cardiometabolic, respiratory, neurological, cancer) and may have many outcomes. The datasets we work with come from many different sources and pose several challenges for analysis.
Integrating population and disease cohorts
In ageing individuals, multiple conditions (e.g. hypertension, stroke and dementia) frequently co-occur and lead to poor outcomes. Adolescents and middle-aged adults may also have traits (e.g. obesity) that are risk factors for these diseases, and these can have an impact on their well-being throughout their lifetime. Few studies have gone beyond epidemiology to examine the biological and molecular basis of multiple long-term conditions across the human lifespan. Observational and experimental studies focusing on one condition at a time will miss the physiological and molecular characteristics that are common between diseases. Our vision is to redefine the diagnosis of diseases using molecular and physiological traits, leveraging data from multiple cohorts and using machine learning techniques. One of our current studies is exploring the effects of gene-lipid interactions on child and mother mental health using multi-omic data from the GUSTO, S-PRESTO and ALSPAC birth cohorts. We also link early-life risk factors to cardiovascular and neurodegenerative disease cases in later life using ageing cohorts, such as ATTRaCT, UK Biobank, SG100K. To identify more generalizable risk factors, we actively work with informatics colleagues in academia and industry to develop and test federated data platforms for analysing cohorts across different countries and jurisdictions.
Modelling and machine learning
Since the factors contributing to the development of complex diseases may come from multiple sources, including genetics, epigenetics, lifestyle and the environment, we must consider many different molecular and health-related readouts collected from individuals over time. We actively use statistical and machine learning models to predict future health outcomes with the different readouts from molecular (-omics) assays and wearable sensors. These include classification algorithms that employ feature selection and dimensionality reduction to untangle the heterogeneity of pulmonary hypertension, COVID-19, and dementia. Probabilistic models to describe longitudinal changes in epigenetic ageing and drug response. And regression-based methods to perform Mendelian randomization and generate polygenic scores. We often collaborate with our sister team at Imperial College London to improve these techniques.

Figure 1: Global Impact of Data Vault
OHDSI OMOP Data Curation and Analytics
Establishing Singapore’s OMOP clinical and multi-Omics data standards for MOH TRUST strategic research datasets, the group is leading the national capabilities for OMOP data curation and analytics by partnering with the global OHDSI community. The group is leading the OHDSI APAC Scientific Forums at a global collaborative ecosystem, catalyzing Singapore’s OHDSI OMOP efforts. The GUSTO OMOP Data Catalogue won the Best Community Contribution Award at 2023 OHDSI Global Symposium held at New Jersey (USA).

Figure 2: Global Leadership with OHDSI Community
Synthetic Data Applications
The group is spearheading the privacy preserving machine learning development with DataCebo’s Synthetic Data Vault (SDV) and OpenAI’s large language models for predictive AI use cases (in alignment with Singapore’s National AI Strategy 2.0 to build capabilities in data services and privacy-enhancing technologies).
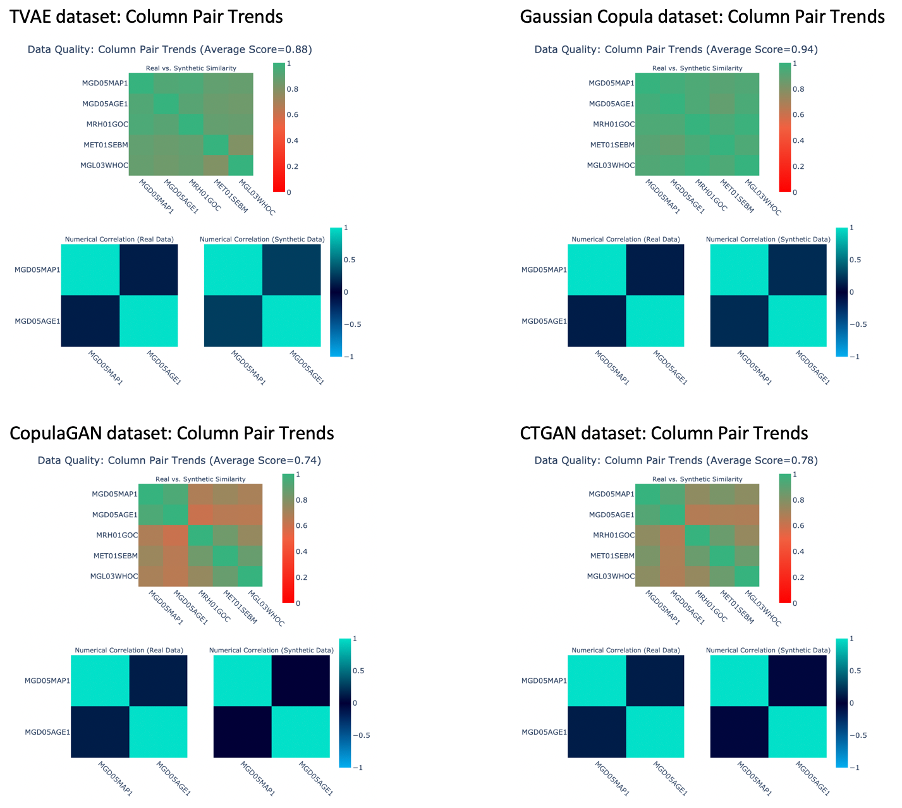
Figure 3: Correlation Heatmap of Synthetic Datasets Generated with DataCebo’s Synthetic Data Vault
Generative AI Applications
The group is scaling up the application of Large Language Models (LLM) for Question-Answering system of research literature in the Data Vault (literature review was the most impactful strategic area identified by A*STAR’s Generative AI Task Force for Research).
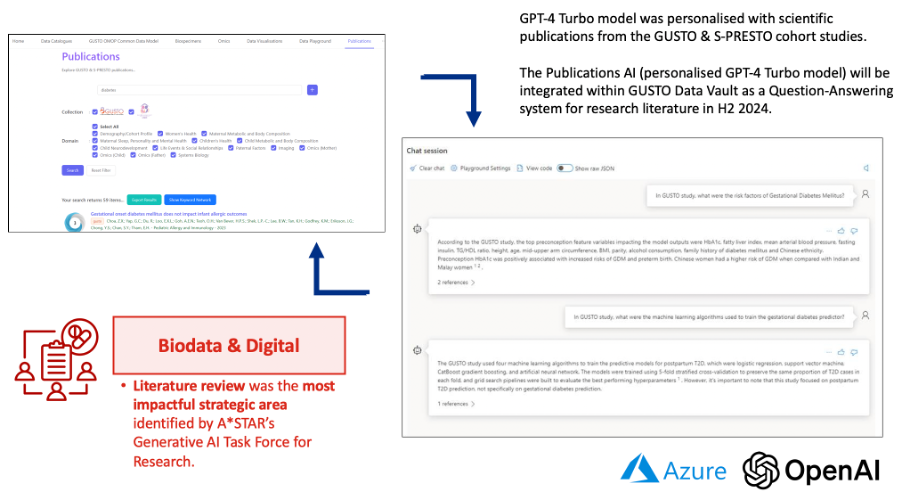
Figure 4: AI-assisted Question-Answering System for Research Literature
| Lead Research Officer | P Mukkesh KUMAR | [View Bio] |
| Lead Research Officer | ERWIN Tantoso |
| Senior Research Officer | ANG Li Ting |
| Senior Research Officer | CHOH Mei Kit |
| Senior Research Officer | CHOO Sok Hui Sue |
| Senior Research Officer | HO Xin Ying Cindy |
| Senior Research Officer | ISMAIL Bin Mohd |
| Senior Research Officer | NG Mei Xi Maisie |
| Senior Research Officer | TAN Shuen Lin |
| Senior Research Officer | YE Yingxin Estella |
| Research Officer | PNG Hang |
| Research Officer | TAN Jing Yang |
- GUSTO Data Vault: Laying the foundations for an open science system with OMOP Data Catalogue - Best Community Contribution Honoree
2023 Observational Health Data Science and Informatics (OHDSI) Global Symposium, New Jersey, USA. Ho C1,2, Ang LT1,2, Ng M1,2, Png H1,2, Tan SL1,2, Ye E1,2, Raja SK2, Feng M3, Eriksson JG2,3,4, Kumar M1,2
1BII, 2SICS, 3NUS, 4 Univ. of Helsinki. October 2023.
The GUSTO OMOP Data Catalogue have laid the foundations for developing cross-study OMOP Data Catalogues expanded across APAC and global OHDSI data partners, leading towards the development of the ATTRaCT OMOP Data Catalogue.
P Mukkesh Kumar
 | P Mukkesh KUMAR Lead Research Officer Email: mukkesh_kumar@a-star.edu.sg Research Group: Data Management |
Dr P Mukkesh Kumar is the Head of Data Management Platform at A*STAR’s Bioinformatics Institute (BII) and Singapore Institute for Clinical Sciences (SICS), leading the Multi-modal Data Management, Data Curation & Data Stewardship, Healthcare Data Analytics & Reporting and Healthcare Software Development teams. Dr P Mukkesh Kumar is a PhD alumnus of the NUS Saw Swee Hock School of Public Health, he has developed a predictive care framework for diabetes & maternal health, combining coalitional game theory concepts with machine learning. Forging collaborations with the National University Hospital (NUH) in Value-based Healthcare Strategy, the Early Screening for Gestational Diabetes Mellitus in a Low Risk Population (EaGeR) pilot study conducted at NUH for the real world deployment of early pregnancy GDM predictor AI model. Working in close partnership with Singapore’s Ministry of Health (MOH), Dr P Mukkesh Kumar is developing the core OMOP data curation team at A*STAR to support MOH-TRUST Strategic Research Data Contributors. Dr P Mukkesh Kumar has been mentoring the Data Managers at US Boston Children’s Hospital/Harvard Medical School for multi-centre clinical research studies, building talent and capabilities in the global research ecosystem.
Group Member