
We are a team of computational scientists from diverse educational backgrounds (biology, engineering, physics, medicine, mathematics) based at the Singapore Institute for Clinical Sciences and the Bioinformatics Institute. Our central mission is to identify the determinants of population health using molecular profiling and machine learning approaches. The cohorts we investigate are composed of individuals affected by complex health conditions (cardiometabolic, respiratory, neurological, cancer) and may have many outcomes. The datasets we work with come from many different sources and pose several challenges for analysis.
Integrating population and disease cohorts
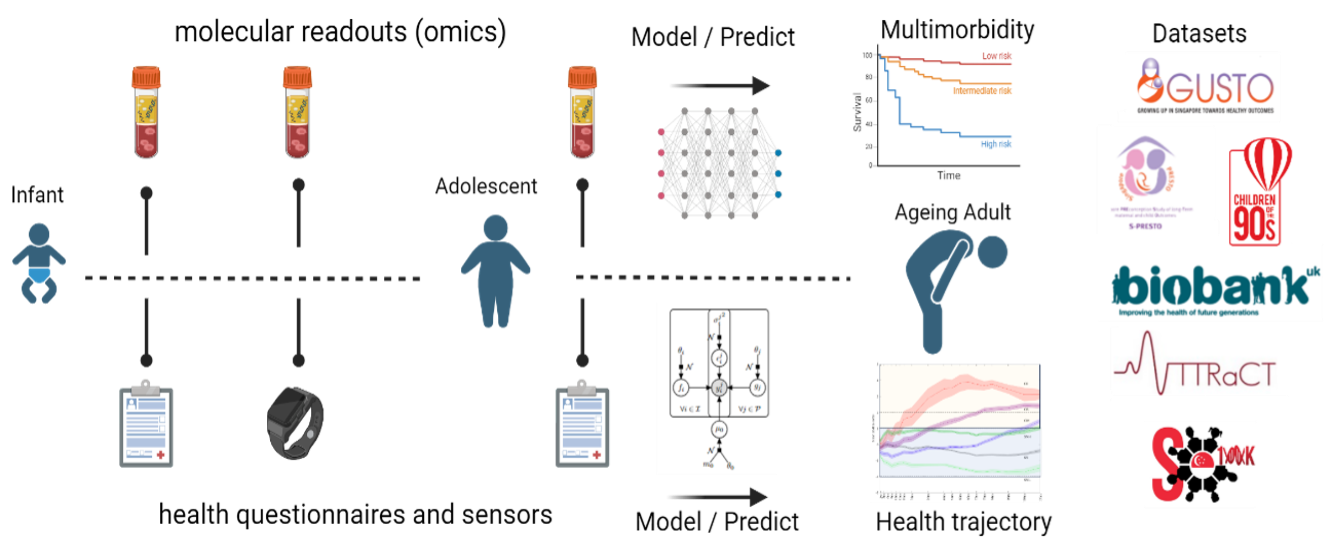
In ageing individuals, multiple conditions (e.g. hypertension, stroke and dementia) frequently co-occur and lead to poor outcomes. Adolescents and middle-aged adults may also have traits (e.g. obesity) that are risk factors for these diseases, and these can have an impact on their well-being throughout their lifetime. Few studies have gone beyond epidemiology to examine the biological and molecular basis of multiple long-term conditions across the human lifespan. Observational and experimental studies focusing on one condition at a time will miss the physiological and molecular characteristics that are common between diseases. Our vision is to redefine the diagnosis of diseases using molecular and physiological traits, leveraging data from multiple cohorts and using machine learning techniques. One of our current studies is exploring the effects of gene-lipid interactions on child and mother mental health using multi-omic data from the GUSTO, S-PRESTO and ALSPAC birth cohorts. We also link early-life risk factors to cardiovascular and neurodegenerative disease cases in later life using ageing cohorts, such as ATTRaCT, UK Biobank, SG100K. To identify more generalizable risk factors, we actively work with informatics colleagues in academia and industry to develop and test federated data platforms for analysing cohorts across different countries and jurisdictions.
Modelling and machine learning
Since the factors contributing to the development of complex diseases may come from multiple sources, including genetics, epigenetics, lifestyle and the environment, we must consider many different molecular and health-related readouts collected from individuals over time. We actively use statistical and machine learning models to predict future health outcomes with the different readouts from molecular (-omics) assays and wearable sensors. These include classification algorithms that employ feature selection and dimensionality reduction to untangle the heterogeneity of pulmonary hypertension, COVID-19, and dementia. Probabilistic models to describe longitudinal changes in epigenetic ageing and drug response. And regression-based methods to perform Mendelian randomization and generate polygenic scores. We often collaborate with our sister team at Imperial College London to improve these techniques.
| Senior Principal Scientist | WANG Dennis | [View Bio] |
| Principal Scientist | PAN Hong |
| Senior Scientist | GUPTA Varsha |
| Senior Scientist | HUANG Jian |
| Senior Scientist | LAU Evelyn |
| Senior Scientist | VAZ Candida |
| Scientist | MISHRA Priti |
| Lead Research Officer | TEH Ai Ling |
| Senior Research Officer | TAN Pei Fang |
| Research Officer | CHE Jinyi |
| Research Officer | ZHANG Xiaohe |
 | WANG Dennis Senior Principal Scientist Email: Dennis_Wang@a-star.edu.sg Research Group: Data Science for Population Health |
Dennis Wang is a Senior Principal Scientist at the A*STAR Singapore Institute for Clinical Sciences and Bioinformatics Institute, and also the Academy of Medical Sciences Professor (Chair in Data Science) at Imperial College London. Having worked in both academia and industry, he enjoys mentoring early-career data scientists and clinical researchers wanting to make an impact on human health using data-driven techniques. Prior to the pandemic, he was a researcher at the University of Sheffield, AstraZeneca and Microsoft Research. He obtained his Bachelor of Science in Computer Science and Microbiology from The University of British Columbia, and his MPhil in Computational Biology and PhD in Biostatistics from the University of Cambridge.